Lipsyncing with Papagayo
iaian7 » tutorials » aftereffects John Einselen, 25.09.09 (updated 13.01.10)Using freely available tools, lipsyncing a character in Adobe After Effects doesn’t have to be a pain. Papagayo is an open source app for breaking a script down into phonemes and syncing the pieces to an audio track, while LipSync is an OS X dashboard widget that helps translate the resulting moho switch files into After Effects keyframes.
The workflow was developed at Vectorform as part of the production pipeline for Microsoft’s PowerPivot online advertising campaign (to see how the torn effects were created, check out Dynamic Paper Cutouts).
Composition Setup
Papagayo uses the Preston-Blair phoneme set, so we’ll need to set up a pre-comp in After Effects with a single phoneme each frame, with (at minimum) the following, and in this order:
AI, E, FV, L, MBP, O, U, WQ, etc, rest
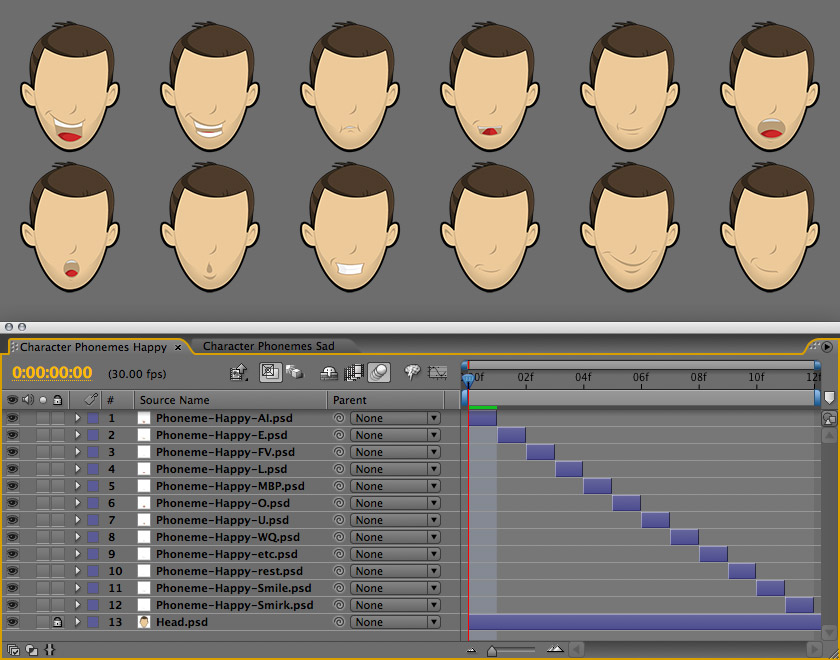 For the Microsoft PowerPivot project, a separate pre-comp was created for both happy and sad faces, and the comps switched out depending on the desired mood. However, the details are entirely up to you; a more extensive comp with a phoneme at every second and mood variations on every frame would also work, though it would require a frame offset setup to control the mouth expression. Fairly easy with basic knowledge of expressions, but not covered by this tutorial.
For the Microsoft PowerPivot project, a separate pre-comp was created for both happy and sad faces, and the comps switched out depending on the desired mood. However, the details are entirely up to you; a more extensive comp with a phoneme at every second and mood variations on every frame would also work, though it would require a frame offset setup to control the mouth expression. Fairly easy with basic knowledge of expressions, but not covered by this tutorial.
Audio prep

 The final audio edit for this project was split into paragraphic chunks to make syncing easier. It’s all about breaking the process down into manageable pieces. Each piece was exported as it’s own audio file, and compressed using Quicktime Pro into a .wav file using LinearPCM set to output high quality stereo. Mono should work as well (some lipsync applications such as Yolo and JLipSync can work better with Mono), so it’s up to your preference.
The final audio edit for this project was split into paragraphic chunks to make syncing easier. It’s all about breaking the process down into manageable pieces. Each piece was exported as it’s own audio file, and compressed using Quicktime Pro into a .wav file using LinearPCM set to output high quality stereo. Mono should work as well (some lipsync applications such as Yolo and JLipSync can work better with Mono), so it’s up to your preference.
Lipsync
 Open up Papagayo and import the .wav audio clip. In OS X, there’s a bug with the Frames Per Second input field – you can’t type numerals. To get around this, open up TextEdit and type your desired fps, copy it to the clipboard, then back in Papgayo, paste it into the field using
Open up Papagayo and import the .wav audio clip. In OS X, there’s a bug with the Frames Per Second input field – you can’t type numerals. To get around this, open up TextEdit and type your desired fps, copy it to the clipboard, then back in Papgayo, paste it into the field using command+v. It’s important to do this before you start editing phoneme timing, as changing the value will completely reset script pieces to the default positions. If you have trouble with Papagayo not recognizing the correct length of your audio (for example, preventing script pieces from being dragged to the end of the audio), try pasting in a different FPS value, then the correct one again. This should force the app to refresh, correcting the audio settings.
 In the Spoken Text field, enter the script. It’ll be helpful to enter a carriage return at natural breaks or pauses, as Papagayo will treat each line as an individual chunk of text. Numerals should be spelled out, otherwise the automatic phoneme dictionary will fail to recognize them.
In the Spoken Text field, enter the script. It’ll be helpful to enter a carriage return at natural breaks or pauses, as Papagayo will treat each line as an individual chunk of text. Numerals should be spelled out, otherwise the automatic phoneme dictionary will fail to recognize them.
“It all started with my second cup of coffee. Eh, no, my 3rd… it’d been a long Friday, when an email from the boss attacked.”
Should be written as:
“It all started with my second cup of coffee
Eh, no, my third
it’d been a long Friday
when an email from the boss attacked”
 Once you have the script ready to go, select a language from the several listed under Phonetic Breakdown to automatically generate phonemes. If the phoneme translation engine encounters anything it doesn’t recognize, you’ll be prompted to enter your own phonetical spelling. It helps to be familiar with the Preston-Blair phoneme set and the specific mouth shapes your final animation will use, as phoneme shapes rarely line up with how a word is spelled or pronounced, but how an individual speaker says it.
Once you have the script ready to go, select a language from the several listed under Phonetic Breakdown to automatically generate phonemes. If the phoneme translation engine encounters anything it doesn’t recognize, you’ll be prompted to enter your own phonetical spelling. It helps to be familiar with the Preston-Blair phoneme set and the specific mouth shapes your final animation will use, as phoneme shapes rarely line up with how a word is spelled or pronounced, but how an individual speaker says it.
 Starting with the last phrase block, line up the beginning and end with the correct section of audio. You can either press the play button (which starts from the beginning), or scrub through manually (clicking anywhere in the audio window and dragging back and forth). Give yourself enough frames at the start and end of each clip so as to allow for a little wiggle room. Rearranging the sentences later will undo any fine-tuning you’ve completed in the word and phoneme levels, so getting each level worked out in the proper order helps prevent lost work.
Starting with the last phrase block, line up the beginning and end with the correct section of audio. You can either press the play button (which starts from the beginning), or scrub through manually (clicking anywhere in the audio window and dragging back and forth). Give yourself enough frames at the start and end of each clip so as to allow for a little wiggle room. Rearranging the sentences later will undo any fine-tuning you’ve completed in the word and phoneme levels, so getting each level worked out in the proper order helps prevent lost work.
 Once the sentence fragments are timed correctly, go through and align each word. You can double click any block to play the corresponding audio, and right click any word to edit the phonemes currently used. With judicious use of phonemes, you may not even have to manually adjust them, but inevitably you’ll need to tweak a few phoneme positions as well.
Once the sentence fragments are timed correctly, go through and align each word. You can double click any block to play the corresponding audio, and right click any word to edit the phonemes currently used. With judicious use of phonemes, you may not even have to manually adjust them, but inevitably you’ll need to tweak a few phoneme positions as well.
Typically, a phoneme should start a frame before the corresponding sound. Punctuated phonemes such as “P” or “B” can often start several frames or more ahead of the sound, and consonants sometimes need an extra frame or two to register with the viewer (flashing a consonant for just one, maybe two frames is often not enough time). An “M” sound may seem insignificant, but the pent up pressure is essential to selling the vocal animation. Depending on the recorded audio and your character illustrations, “AI” and “E” may need to be interchanged. For the example audio, Papagayo inserts a lot of “AI” phoneme shapes where “E” would be more appropriate, and vice-versa. Edit the phonemes to match what the audio sounds like, not what the words actually are.
That said, there are innumerable articles, books, classes, and degrees in animation, and I am no character animator myself. This is a starting point, but hardly an introduction to the rich art of animation!
 Once the alignment is polished and the preview animation in Papagayo meets satisfaction, you can export the data as a Moho switch file (
Once the alignment is polished and the preview animation in Papagayo meets satisfaction, you can export the data as a Moho switch file (.dat). This essentially defines a simple list of frames and the associated phoneme shape changes.
Conversion
 Using the Lipsync widget for OS X, this is the easiest part. The defaults are set up for Lightwave, so once installed, change the format to AE frames (or seconds, depending on the pre-comp setup), and you’re ready to go.
Using the Lipsync widget for OS X, this is the easiest part. The defaults are set up for Lightwave, so once installed, change the format to AE frames (or seconds, depending on the pre-comp setup), and you’re ready to go.
To convert, simply click and start dragging the .dat lipsync file while opening Dashboard (usually the f12 or f4 key). Drag it into the “drop MOHO file here” zone and let go. It’ll be automatically converted into Time Remap keyframes, and the results both copied to your clipboard and saved to your hard drive (placed alongside the original .dat file).
Final output


 Back in Adobe After Effects, open the main animation comp, move the playhead to the begining of the comp (or more specifically, to the beginning of the audio clip) and select the phoneme pre-comp. Paste the keyframes copied by LipSync (
Back in Adobe After Effects, open the main animation comp, move the playhead to the begining of the comp (or more specifically, to the beginning of the audio clip) and select the phoneme pre-comp. Paste the keyframes copied by LipSync (command+v), and Time Remap will automatically be applied to the layer. Select all of the keyframes (easiest way to do that is to click the Time Remap title), right-click, and choose Toggle Hold Keyframe, otherwise the phoneme shapes will bounce back and forth, instead of holding till the next one is set.
Make sure it’s in sync with the audio, and you should be all done. Here’s the final video, completed by Vectorform for the Microsoft PowerPivot online advertising campaign.
Watch the final PowerPivot video on YouTube or Vimeo to rate it or leave a comment!
Downloads
Get the exclusive project downloads from the Vectorform blog post.
Adobe and After Effects are either registered trademarks or trademarks of Adobe Systems Incorporated in the United States and/or other countries.
 mediaboxAdvanced
mediaboxAdvanced